 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Memory as Continuously Evolving Connectivity
May 27, 2026Existing memory-augmented LLM agents often treat memory as a static repository with pre-defined representations and fixed retrieval pipelines, which is brittle in dynamic agentic environments where feedback, task variation, and heterogeneous signals continuously reshape what should be remembered and how it should be connected. To address this, we propose FluxMem, a connectivity-evolving memory framework that models memory as a heterogeneous graph and progressively refines its topology through three stages: initial connection formation, feedback-driven refinement, and long-term consolidation. During execution, FluxMem repairs missing links, prunes interference, aligns abstraction granularity, and distills recurrent successful trajectories into reusable procedural circuits, guided by one metric for memory generalizability and evolutionary maturity. Across three fundamentally distinct benchmarks including LoCoMo, Mind2Web, and GAIA, FluxMem achieves consistent state-of-the-art performance, demonstrating strong adaptation and generalization in complex agentic environments. The code will be open-sourced in https://github.com/zjunlp/LightMem.
MemTrace: Tracing and Attributing Errors in Large Language Model Memory Systems
May 27, 2026Memory is essential for enabling large language models to support long-horizon reasoning, yet existing memory systems remain unreliable and difficult to debug. Tracing memory's dynamic evolution is crucial to understand how information is synthesized, propagated, or corrupted over time. In this work, we study the new problem of error tracing and attribution in LLM memory systems. We propose a novel framework that transforms memory pipelines into executable memory evolution graphs, enabling fine-grained tracing of operational information flow. We then construct MemTraceBench, a benchmark collected from representative memory systems such as Long-Context, RAG, Mem0, and EverMemOS, to systematically study memory failure modes. We further introduce an automatic attribution method that iteratively traces operation subgraphs to pinpoint the root cause of any failed case. Our analysis reveals that memory failures are systematic, stemming from operation-level issues like information loss and retrieval misalignment. Crucially, we leverage these fine-grained attribution signals to guide downstream prompt optimization, establishing a closed-loop system that automatically corrects faults and boosts end-task performance by up to 7.62%. Code will be released at https://github.com/zjunlp/MemTrace.
Rubrics to Tokens: Bridging Response-level Rubrics and Token-level Rewards in Instruction Following Tasks
Apr 03, 2026Rubric-based Reinforcement Learning (RL) has emerged as a promising approach for aligning Large Language Models (LLMs) with complex, open-domain instruction following tasks. However, existing methods predominantly rely on response-level rewards, introducing severe reward sparsity and reward ambiguity problems. To address these issues, we propose Rubrics to Tokens (RTT), a novel rubric-based RL framework that bridges coarse response-level scores and fine-grained token-level credit assignment. RTT introduces a Token-Level Relevance Discriminator to predict which tokens in the response are responsible for a specific constraint, and optimizes the policy model via RTT-GRPO, which integrates response-level and token-level advantages within a unified framework. Furthermore, when transitioning from one-dimensional, outcome-level reward to three-dimensional reward space in the token-level rubric-based RL, we propose a novel group normalization method, called Intra-sample Token Group Normalization, to accommodate this shift. Extensive experiments and benchmarks demonstrate that RTT consistently outperforms other baselines in both instruction- and rubric-level accuracy across different models.
SkillRouter: Retrieve-and-Rerank Skill Selection for LLM Agents at Scale
Mar 23, 2026As LLM agent ecosystems grow, the number of available skills (tools, plugins) has reached tens of thousands, making it infeasible to inject all skills into an agent's context. This creates a need for skill routing -- retrieving the most relevant skills from a large pool given a user task. The problem is compounded by pervasive functional overlap in community skill repositories, where many skills share similar names and purposes yet differ in implementation details. Despite its practical importance, skill routing remains under-explored. Current agent architectures adopt a progressive disclosure design -- exposing only skill names and descriptions to the agent while keeping the full implementation body hidden -- implicitly treating metadata as sufficient for selection. We challenge this assumption through a systematic empirical study on a benchmark of ~$80K skills and 75 expert-verified queries. Our key finding is that the skill body (full implementation text) is the decisive signal: removing it causes 29--44 percentage point degradation across all retrieval methods, and cross-encoder attention analysis reveals 91.7% of attention concentrating on the body field. Motivated by this finding, we propose SkillRouter, a two-stage retrieve-and-rerank pipeline totaling only 1.2B parameters (0.6B encoder + 0.6B reranker). SkillRouter achieves 74.0% top-1 routing accuracy and delivers the strongest average result among the compact and zero-shot baselines we evaluate, while remaining deployable on consumer hardware.
SERL: Self-Examining Reinforcement Learning on Open-Domain
Nov 18, 2025Reinforcement Learning (RL) has been shown to improve the capabilities of large language models (LLMs). However, applying RL to open-domain tasks faces two key challenges: (1) the inherent subjectivity of these tasks prevents the verifiable rewards as required by Reinforcement Learning with Verifiable Rewards (RLVR); (2) Reinforcement Learning from Human Feedback (RLHF) relies on external reward mechanisms. To overcome these limitations, we propose Self-Examining Reinforcement Learning (SERL), a novel self-improving framework where the LLM serves as both Actor and Judge. SERL introduces two synergistic reward mechanisms without any external signals. On the one hand, to improve the Actor's capability, we derive rewards from Copeland-style pairwise comparison judgments across a group of generated responses. On the other hand, a self-consistency reward that encourages coherent judgments is proposed to improve the Judge's reliability. This process refines the Judge's capability, which in turn provides a more robust reward for Actor. Experiments show that our method outperforms existing self-improvement training methods. SERL improves the LC win rate of Qwen3-8B on AlpacaEval 2 from 52.37% to 59.90%. To the best of our knowledge, our method achieves state-of-the-art performance among self-improving approaches. Furthermore, it achieves a performance comparable to significantly larger models like Qwen3-32B, demonstrating superior effectiveness and robustness on open-domain tasks.
Conifer: Improving Complex Constrained Instruction-Following Ability of Large Language Models
Apr 03, 2024The ability of large language models (LLMs) to follow instructions is crucial to real-world applications. Despite recent advances, several studies have highlighted that LLMs struggle when faced with challenging instructions, especially those that include complex constraints, hindering their effectiveness in various tasks. To address this challenge, we introduce Conifer, a novel instruction tuning dataset, designed to enhance LLMs to follow multi-level instructions with complex constraints. Utilizing GPT-4, we curate the dataset by a series of LLM-driven refinement processes to ensure high quality. We also propose a progressive learning scheme that emphasizes an easy-to-hard progression, and learning from process feedback. Models trained with Conifer exhibit remarkable improvements in instruction-following abilities, especially for instructions with complex constraints. On several instruction-following benchmarks, our 7B model outperforms the state-of-the-art open-source 7B models, even exceeds the performance of models 10 times larger on certain metrics. All the code and Conifer dataset are available at https://www.github.com/ConiferLM/Conifer.
U-NEED: A Fine-grained Dataset for User Needs-Centric E-commerce Conversational Recommendation
May 05, 2023



Conversational recommender systems (CRSs) aim to understand the information needs and preferences expressed in a dialogue to recommend suitable items to the user. Most of the existing conversational recommendation datasets are synthesized or simulated with crowdsourcing, which has a large gap with real-world scenarios. To bridge the gap, previous work contributes a dataset E-ConvRec, based on pre-sales dialogues between users and customer service staff in E-commerce scenarios. However, E-ConvRec only supplies coarse-grained annotations and general tasks for making recommendations in pre-sales dialogues. Different from that, we use real user needs as a clue to explore the E-commerce conversational recommendation in complex pre-sales dialogues, namely user needs-centric E-commerce conversational recommendation (UNECR). In this paper, we construct a user needs-centric E-commerce conversational recommendation dataset (U-NEED) from real-world E-commerce scenarios. U-NEED consists of 3 types of resources: (i) 7,698 fine-grained annotated pre-sales dialogues in 5 top categories (ii) 333,879 user behaviors and (iii) 332,148 product knowledge tuples. To facilitate the research of UNECR, we propose 5 critical tasks: (i) pre-sales dialogue understanding (ii) user needs elicitation (iii) user needs-based recommendation (iv) pre-sales dialogue generation and (v) pre-sales dialogue evaluation. We establish baseline methods and evaluation metrics for each task. We report experimental results of 5 tasks on U-NEED. We also report results in 3 typical categories. Experimental results indicate that the challenges of UNECR in various categories are different.
HIE-SQL: History Information Enhanced Network for Context-Dependent Text-to-SQL Semantic Parsing
Apr 02, 2022
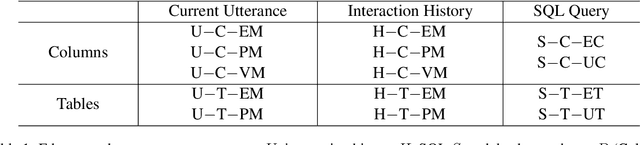
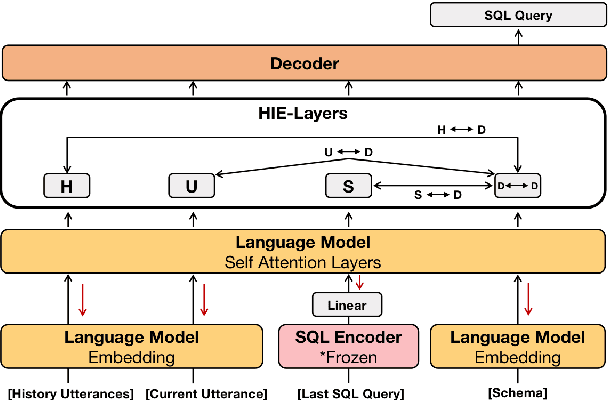

Recently, context-dependent text-to-SQL semantic parsing which translates natural language into SQL in an interaction process has attracted a lot of attention. Previous works leverage context-dependence information either from interaction history utterances or the previous predicted SQL queries but fail in taking advantage of both since of the mismatch between natural language and logic-form SQL. In this work, we propose a History Information Enhanced text-to-SQL model (HIE-SQL) to exploit context-dependence information from both history utterances and the last predicted SQL query. In view of the mismatch, we treat natural language and SQL as two modalities and propose a bimodal pre-trained model to bridge the gap between them. Besides, we design a schema-linking graph to enhance connections from utterances and the SQL query to the database schema. We show our history information enhanced methods improve the performance of HIE-SQL by a significant margin, which achieves new state-of-the-art results on the two context-dependent text-to-SQL benchmarks, the SparC and CoSQL datasets, at the writing time.